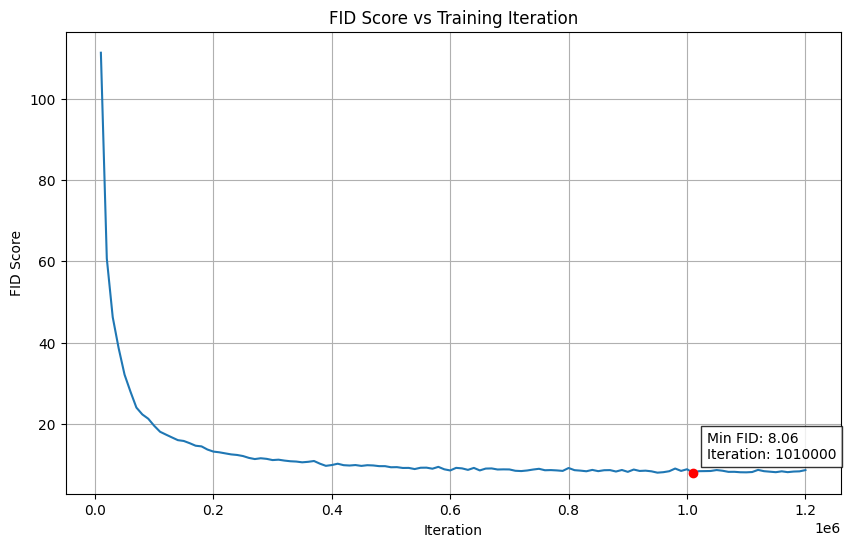
Some of my FID patterns
I provide some of the FID schemes, so you can recognise a bad run. I also provide in the code repo my final FID scheme for the successful model. To be honest, I’m not sure of the exact params each time I ran these models given I did so many training runs, but I hope to provide some examples so that you can see what didnt work for me (next time I will implement better logging and we can explore exactly why each one breaks down).
In the following scrollable output, you will see a few training runs which cover the different break downs I saw.
Here, the training appears to go well. But the GPU, crashed at iter 180k. I restarted training after that from a checkpoint and you see performance just fluctuates, reaching a minimum of 115. To me this is a failed run, as it fails to improve even after 200k iteration (bare in mind this took about 3/4 days).
Iteration 5000: 372.2608947753906
Iteration 10000: 273.1268615722656
Iteration 15000: 260.4564208984375
Iteration 20000: 223.1716766357422
Iteration 25000: 219.0269775390625
Iteration 30000: 205.28900146484375
Iteration 35000: 188.085205078125
Iteration 40000: 177.87722778320312
Iteration 45000: 200.12591552734375
Iteration 50000: 177.63365173339844
Iteration 55000: 175.5360107421875
Iteration 60000: 175.09141540527344
Iteration 65000: 178.38917541503906
Iteration 70000: 170.81842041015625
Iteration 75000: 160.3494415283203
Iteration 80000: 158.06622314453125
Iteration 85000: 159.43179321289062
Iteration 90000: 154.20611572265625
Iteration 95000: 158.0677947998047
Iteration 100000: 143.0650634765625
Iteration 105000: 143.35877990722656
Iteration 110000: 147.93089294433594
Iteration 115000: 128.8855438232422
Iteration 120000: 145.07362365722656
Iteration 125000: 142.61892700195312
Iteration 130000: 129.04664611816406
Iteration 135000: 127.5386734008789
Iteration 140000: 144.24447631835938
Iteration 145000: 145.9493408203125
Iteration 150000: 131.70626831054688
Iteration 155000: 122.86494445800781
Iteration 160000: 133.6108856201172
Iteration 165000: 121.39984893798828
Iteration 170000: 125.3056411743164
Iteration 175000: 133.8019256591797
Iteration 180000: 120.23395538330078
Iteration 185000: 122.73983764648438
Iteration 190000: 123.81011962890625
Iteration 195000: 145.60452270507812
Iteration 200000: 131.8021240234375
Iteration 205000: 131.51727294921875
Iteration 210000: 132.5868682861328
Iteration 215000: 115.08854675292969
Iteration 220000: 119.64303588867188
Iteration 225000: 117.72576141357422
Iteration 230000: 128.736328125
Iteration 235000: 146.3714599609375
Iteration 240000: 134.3799285888672
Iteration 245000: 127.26163482666016
Iteration 250000: 118.39510345458984
Iteration 255000: 133.1106719970703
Another which seemingly starts off well, then fluctuates. We got to a minimum FID of around 94, which is still pretty bad. At this FID images look horrible still.
Iteration 5000: 375.0341491699219
Iteration 10000: 266.1919250488281
Iteration 15000: 225.51492309570312
Iteration 20000: 209.35122680664062
Iteration 25000: 169.07830810546875
Iteration 30000: 162.7826690673828
Iteration 35000: 158.3661346435547
Iteration 40000: 142.1690216064453
Iteration 45000: 138.27444458007812
Iteration 50000: 137.2218780517578
Iteration 55000: 135.9760284423828
Iteration 60000: 119.19623565673828
Iteration 65000: 119.33064270019531
Iteration 70000: 113.0389175415039
Iteration 75000: 108.53450775146484
Iteration 80000: 111.82980346679688
Iteration 85000: 109.79493713378906
Iteration 90000: 104.31437683105469
Iteration 95000: 110.7328872680664
Iteration 100000: 122.6935043334961
Iteration 105000: 110.53292083740234
Iteration 110000: 105.91259765625
Iteration 115000: 98.43663787841797
Iteration 120000: 106.87227630615234
Iteration 125000: 100.67845916748047
Iteration 130000: 96.66962432861328
Iteration 135000: 94.45530700683594
Iteration 140000: 100.49161529541016
Iteration 145000: 109.65937042236328
Iteration 150000: 95.66574096679688
Iteration 155000: 106.8659896850586
Iteration 160000: 108.08671569824219
This run performed quite well, the FID drops a lot quicker than previous runs. Here is when I set LR=0.00015625. However, once again it just fluctuates after iter 70k.
Iteration 5000: 400.09442138671875
Iteration 10000: 224.55154418945312
Iteration 15000: 199.23419189453125
Iteration 20000: 166.6976776123047
Iteration 25000: 133.10545349121094
Iteration 30000: 122.34843444824219
Iteration 35000: 116.79188537597656
Iteration 40000: 106.47919464111328
Iteration 45000: 103.15625
Iteration 50000: 97.2866439819336
Iteration 55000: 88.9021987915039
Iteration 60000: 92.6580810546875
Iteration 65000: 87.99129486083984
Iteration 70000: 86.91797637939453
Iteration 75000: 82.1233139038086
Iteration 80000: 82.40524291992188
Iteration 85000: 77.69095611572266
Iteration 90000: 76.31440734863281
Iteration 95000: 76.78862762451172
Iteration 100000: 82.9169692993164
Iteration 105000: 81.16597747802734
Iteration 110000: 78.42939758300781
Iteration 115000: 79.91007232666016
I don’t have any saved FID schemes for the early failures I described. But I will create an example one so you know what to look out for. This might not be exactly what you see but the pattern will be close enough to recognise from this example.
I hope you find these useful!